俄罗斯科学家使用超级计算机探测Google量子处理器的极限
CPQM的量子信息处理实验室与CDISE的超级计算团队“Zhores”合作以模拟Google的量子处理器。按照与Google最近的实验相同的统计数据复制无噪音数据,该团队能够指出Google的数据中潜藏着微妙的效应。这种效应被称为可及性缺失,是由Skoltech团队在过去的工作中发现的。

数值学证实,Google的数据处于所谓的、依赖密度的雪崩的边缘,这意味着未来的实验将需要明显更多的量子资源来进行量子近似优化。
从数值计算的早期开始,量子系统就显得极其难以模仿,尽管其确切原因仍然是一个积极研究的课题。尽管如此,经典计算机模拟量子系统的这种明显固有的困难促使一些研究人员翻转了叙述。
理查德·费曼和尤里·马宁等科学家在20世纪80年代初推测,那些似乎使量子计算机难以用经典计算机模拟的未知成分本身可以作为一种计算资源使用。例如,量子处理器应该善于模拟量子系统,因为它们是由相同的基本原理支配的。
这样的早期想法最终让Google和其他科技巨头创造了期待已久的量子处理器的原型版本。值得注意跌势,这些现代设备很容易出错,它们只能执行最简单的量子程序,而且每次计算都必须重复多次,以平均误差,最终形成一个近似值。
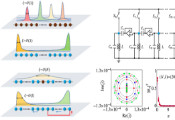
在这些当代量子处理器的应用中,研究最多的是量子近似优化算法,或QAOA(发音为“kyoo-ay-oh-ay”)。在一系列戏剧性的实验中,Google使用其处理器探测QAOA的性能,使用23个量子比特和三个可调整的程序步骤。
简而言之,QAOA是一种方法,其目的是在一个由经典计算机和量子协处理器组成的混合设置上近似解决优化问题。原型的量子处理器,如Google的Sycamore目前被限制在执行噪音和有限的操作。使用混合设置,希望能够减轻这些系统性的限制,并仍然恢复量子行为以利用,这使得QAOA等方法特别有吸引力。
Skoltech的科学家们最近取得了一系列与QAOA有关的发现。其中最突出的是一个从根本上限制QAOA适用性的效应。他们表明,一个优化问题的密度,即其约束条件和变量之间的比率是实现近似解的主要障碍。以在量子协处理器上运行的操作而言,需要额外的资源来克服这一性能限制。这些发现是用纸笔和非常小的仿真器完成的,研究人员希望证实他们最近发现的效果是否在Google最近的实验研究中表现出来。
Skoltech的量子算法实验室随后与Oleg Panarin领导的CDISE超级计算团队接洽,以获得模拟Google量子芯片所需的大量计算资源。量子实验室成员、高级研究科学家Igor Zacharov博士与其他几个人合作,将现有的仿真软件转变为允许在Zhores上进行并行计算的形式。几个月后,该团队成功创建了一个仿真,该仿真输出的数据具有与Google相同的统计分布,并显示了QAOA性能急剧下降的实例密度范围。他们进一步显示,Google的数据位于这个范围的边缘,超过这个范围,目前的技术水平不足以产生任何优势。
Skoltech团队最初发现,可达性缺陷--一种由问题的约束与变量比率引起的性能限制存在于一种叫做最大约束满足性的问题中。而Google则考虑了图能量函数的最小化。由于这些问题属于同一复杂度类别,这给团队带来了概念上的希望,即这些问题,以及后来的效果,可能是相关的。这一直觉被证明是正确的。数据产生后,研究结果清楚地表明,可达性缺陷产生了一种雪崩效应,使Google的数据处于这种快速转变的边缘,超过这个边缘,更长、更强大的QAOA电路就成为一种必要。
Skoltech公司的数据和信息服务经理Oleg Panarin评论说。“我们非常高兴看到我们的计算机被推到这个极端。这个项目是漫长而富有挑战性的,我们与量子实验室携手合作,开发了这个框架。我们相信这个项目为未来使用Zhores进行这种类型的演示设定了基线。”
Skoltech公司的高级研究科学家Igor Zacharov补充说:“我们从这项研究的第一作者Akshay Vishwanatahan那里获得了现有的代码,并把它变成了一个可以并行运行的程序。当数据最终出现时,对我们所有人来说是一个激动人心的时刻:我们拥有了与Google一样的统计数据。在这个项目中创建的软件包现在可以模拟各种最先进的量子处理器,有多达36个量子比特和十几层深度”。
Skoltech的博士生Akshay Vishwanatahan总结说。“在QAOA中超过几个量子比特和几层,在当时是一项具有明显挑战性的任务。我们开发的内部仿真软件只能解决玩具模型的情况,我最初觉得这个项目虽然是一个令人兴奋的挑战,但几乎不可能完成。幸运的是,我身处一群乐观和积极的同行之中,这进一步激励我坚持下去,重现Google的无噪音数据。当我们的数据与Google的数据相匹配时,当然是一个非常兴奋的时刻,因为我们的数据具有类似的统计分布,从中我们终于能够看到效果的存在。”